

|
|
|
In den nächsten Kapiteln beschäftigen wir uns mit fortgeschrittenen Sprachelementen und bewegen uns schon relativ weit weg von QBasic. Daher liegt es nahe, nun die "-lang fblite"-Option wegzulassen. Das bedeutet in erster Linie: Option explicit weglassen; alle Variablen müssen nun wie in Pascal oder C++ zwingend deklariert werden. Und zweitens: Standardmässig geschehen Variablenübergaben in Subs und Functions by value und nicht by reference.
Dieses und die nächsten zwei Kapitel sind für Programmiereinsteiger harter Stoff. Es wird nichts vorausgesetzt, was nicht schon erklärt worden wäre, aber das eben Gelernten muss schon souverän beherrscht werden, wenn man die neuen Gedanken flüssig aufnehmen können will. Wenn Sie nicht mehr durchsteigen: Scheuen Sie sich nicht, einfach mit den nachfolgenden Kapiteln jenseits von "Container" weiterzumachen. Dort werden sie nicht vorausgesetzt.
Um was geht es? Um zwei Dinge. Inhaltlich geht es uns schlicht um einen modernen Ersatz für unsere bisherigen Arrays. Wir haben in den Vorkapiteln einige Versuche gestartet, die Speichertechnik für einen schlichten Editor zu entwerfen. Aber wir sind doch immer wieder an unschöne Grenzen gestossen beim Versuch, keine künstlichen Speichergrenzen nach der Art "maximal 10000 Zeilen" einzuziehen. Jetzt werden wir das lässig schaffen. Und werden die neuen Speichertechniken auch sonst gut gebrauchen können. Z.B. entfällt das lästige Suchen nach dem richtigen Index, wenn wir ein ganz bestimmtes Array-Element suchen. Suchen wir z.B. in einem Array mit Identifikationsnummen ("ID's") nach einer bestimmten ID, so lautet das in Zukunft: "x=omalist_find(data,id)".
Wir bewegen uns aber damit nebenbei auch in wichtige Gebiete der objektorientierten Programmierung (OOP). Objektorientiert? Schreibfehler? Freebasic kennt doch keine Objekte (bisher)! Falsch. Man kann mit Freebasic nicht objektorientiert programmieren, wie es die Informatik-Lehrbücher vorschreiben. Richtig. Aber man kann schon einige Konzepte davon realisieren. Und eines ist das Konzept der "Container". Was ist ein "Container"? Nun, das sind schlicht Methoden und Datentypen, die sich nicht auf konkrete weitere Datentypen beziehen. Wenn wir also einen neuen Datentyp "tomalist" erschaffen, so ist zu fragen, was in dieser Liste gespeichert werden soll: Integer, Double, Strings, tsprite oder tclock? Egal. Wir schreiben tomalist so, dass es je nach Bedarf alle, auch noch so komplexe Datentypen aufnehmen kann. Deshalb nennt man tomalist dann einen "Containertyp".
Leider geht das in Freebasic noch nicht so elegant wie in Smalltalk, Python oder Ruby, den reinen Vertretern der OOP. Es ist etwas umständlich, die Daten, die wir speichern wollen, in die Form zu bringen, die unsere Container dann schlucken. Aber auch für dieses Problem gibt es in der Informatik eine Lösung: Man schreibt sich "Wrapper". "Wrap" = Einwickeln. Wir wickeln unsere allgemeinen Container mit kleinen, einfachen, datentypenspezifischen Get- und Put-Routinen ein, die uns diese Umformungsarbeit abnehmen. Das ist immer noch wesentlich einfacher als für jeden Datentyp neu eine komplette Listenbehandlung zu schreiben.
Schliesslich lernen wir bei den Hashes auch noch das Konzept der "Callback-Funktionen" kennen. Und die treffen wir dann beim GUI-Programmieren in ein paar Kapiteln wieder an. Dort werden wir sie nur passiv brauchen, aber hier lernen wir auch, wie man so etwas aktiv in seine Programme einbaut.
Insgesamt sind diese neuen Konzepte unverzichtbar, wenn wir leistungsfähige Programme schreiben wollen. Nehmen wir eine Simulation des Strassenverkehrs. Sie haben ein Strassennetz und müssen erstens alle Autos insgesamt speichern, aber auch alle Autos, die sich jeweils auf einer Strasse befinden. Wieviel Speicherplatz sehen Sie für jede Strasse vor? Wenn's dumm läuft, versammeln sich mal ganz viele Autos auf einer kleinen Nebenstrasse. Ist nicht so gut, wenn dann plötzlich kommt: "Range Check Error" oder "Array too small". Wenn Sie auf der anderen Seite für jede kleine Strasse vorsehen, dass zur Not dort sämtliche Autos gespeichert werden können, dann könnte der Speicherbedarf Ihres Programms schnell in die Multi-Gigabyte-Region vorstossen - auch keine Alternative. Und so werden Listen, Hashes und Bäume sehr schnell zu den zentralen Datentypen, auf denen Sie Ihr Programm aufbauen.
Ich kann mir nicht verkneifen, zu bemerken, dass wir hier natürlich auch so nebenbei das ein oder andere Vorurteil widerlegen. Wir stossen hier ins zweite Semester Informatik vor - und das ohne jede Verrenkung mit dem viel verpönten Basic. Wir beschäftigen uns mit Containern - ohne von OOP etwas gehört zu haben. Wir erlernen sehr moderne Konzepte - und die ach so altmodischen Zeiger spielen dabei die zentrale Rolle. Und schliesslich sind wir Omas, Schüler oder Hausfrauen und können nach dem Beherrschen dieser Kapitel doch besser programmieren als manch einer, der damit seinen Lebensunterhalt verdient...

Eine Liste funktioniert an sich wie ein Eisenbahnzug: Jedes Datenelement ist an einen Vorgänger und einen Nachfolger gekoppelt. Wie? Nun, wie könnte es anders sein, über Zeiger. Die Lokomotive ist das erste Element, das Startelement in der Liste. Wir können sehr leicht alle Elemente der Liste durchlaufen, indem wir über die Zeiger von Waggon zu Waggon hüpfen. Und wir müssen nirgends festlegen, wie lang der Zug maximal sein darf. Kommt noch ein Waggon dazu, hängen wir ihn einfach hinten dran. Der Riesenvorteil: Die einzige statische Reservierung, die wir vornehmen müssen, ist die eines einzigen Elements, der Lokomotive. Eine leere oder fast leere Liste nimmt damit auch praktisch keinen Speicherplatz in Anspruch. Und noch ein Vorteil: Es kann keine Boundary Errors geben. Der Index kann nie die Grenzen überschreiten, weil es weder einen Index noch Grenzen gibt.
Natürlich haben Listen auch einen gewaltigen Nachteil: Der wahlfreie Zugriff auf ein bestimmtes Element ist langwierig. Denn es muss immer gesucht werden. Das heisst, wir müssen immer die ganze Liste von vorne weg absuchen. Bei grossen Listen kostet das natürlich viel Zeit. Dieses Problem gehen Hashes an. Hashes sind mit Listen sehr verwandt, sind aber anspruchsvoller aufgebaut und erlauben sehr viel schnellere Zugriffe.
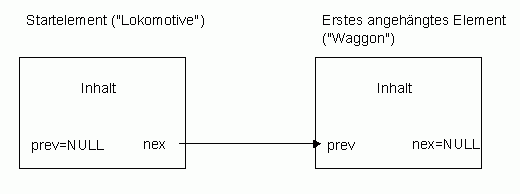
Wir definieren also eine Liste im Wesentlichen einmal durch einen Datentyp, der drei Dinge enthält: Den Inhalt, einen Zeiger zum Vorgänger und einen Zeiger zum Nachfolger. Bauen Sie auf diese Art und Weise einmal eine Liste mit zwei Elementen: Sie definieren den Elementtyp, Sie deklarieren zwei Elemente, belegen Sie mit Inhalten und verketten sie miteinander. Zeiger, die nirgendwo hin zeigen, weil es keinen Nachfolger und keinen Vorgänger gibt, belegen Sie mit dem NULL-Zeiger.
So, hat es geklappt? Der Datentyp könnte z.B. so ausschauen:
TYPE tomalist_element prev AS tomalist_element PTR nex AS tomalist_element PTR cont AS STRING*80 END TYPE
Wir brauchen hier eine rekursive Definition: Wir benutzen einen Zeiger auf einen Datentyp, bevor dieser ganz fertig definiert wurde. Zum Glück verhält sich hier Freebasic sehr elegant und erkennt von selbst, was wir hier vorhaben. (In anderen Sprachen muss man so etwas als "forward" deklarieren o.ä.)
Als Inhalt haben wir hier einen 80 Zeichen langen String genommen. "prev" steht übrigens für "previous", "nex" für "next", was wir nicht ausschreiben können, da "next" ein Basic-Schlüsselwort ist. Und "cont" steht für "content" = Inhalt.
Wir könnten natürlich jetzt einfach ein Array aus zwei solcher Elemente schaffen:
dim as tomalist_element x(2)
Aber genau das ist ja nicht Ziel der Sache. Das jeweils nächste Element existiert zunächst nur in Form eines Zeigers. Also müssen wir den zugehörigen Speicherplatz mit allocate() beschaffen. Und da wir das bei mehr oder weniger allen Elementen so machen müssen, machen wir es beim ersten natürlich gleich auch so. Am Anfang war also nichts anderes als ein Zeiger auf ein Listenelement!
DIM AS tomalist_element PTR start
Das ist unsere ganze Liste! Nichts als ein Startzeiger. Und von da geht es dann los:
start=ALLOCATE(tomalist_element)
IF (start=0) THEN brkmess("War nix")
'Jetzt koennen wir in start etwas speichern:
start->cont="Teststring Lok"
'Nicht vergessen! Gleich alle Leerzeiger mit NULL-Stoepsel versehen!
start->prev=NULL
'Und nun gibts ein neues Element
start->nex=ALLOCATE(tomalist_element)
start->nex->cont="Teststring 1. Waggon"
'Und gleich die Zeiger richtig verketten:
start->nex->prev=start
'Kein 2. Waggon bisher
start->nex->nex=NULL
So, das ist das Grundprinzip. Erweitern Sie das nun mal, indem Sie den Benutzer angeben lassen, wieviel und welche Strings er speichern möchte. Speichern Sie dann alle eingegebenen Strings in einem File.
Nun haben wir noch ein Problem: Nach Ende des Programms müssen wir den reservierten Speicheplatz wieder freigeben. Aber der Speicherplatz ist reichtlich verstreut und nirgendwo ist ein Array, wo die ganzen Zeiger drinstehen würden. Daher müssen wir ein bisschen trickreicher vorgehen: Wir nehmen das Startelement, gehen zum nächsten Element und geben von da das Startelement frei:
'Schliessen der 2-Elemente-Liste: DIM AS tomalist_element PTR curr curr=start->nex DEALLOCATE curr->prev DEALLOCATE curr
Bei mehr Elementen muss man das entsprechend öfters wiederholen: Weiterspringen, Vorgänger löschen, Weiterspringen, Vorgänger löschen. Das Ende der Liste erkennen wir immer durch die NULL im nex-Zeiger.
Nun können wir sehr viel flexibler an die Stelle des 80-Zeichen-Strings auch einen zstring ptr setzen. Der String dann nur 2 Bytes, aber auch 2 GB gross sein, je nach Bedarf. Allerdings müssen wir den entsprechenden Speicherplatz für jeden Eintrag manuell reservieren. Wandeln Sie einmal Ihr bisheriges Übungsprogramm auf zstring ptr ab!
Noch allgemeiner wird's, wenn wir an die Stelle des "zstring ptr" einen "any ptr" setzen. Die Frage ist nur: Was fangen wir damit an?
Nehmen wir einen Testdatentyp und einen any Zeiger:
type ttestdata s AS STRING*80 i AS INTEGER END type DIM AS ttestdata DATA DIM AS ANY PTR px
Wenn wir nun versuchen, px=@data zu bilden, kriegen wir einen Typ-Error: Die Typen passen nicht aufeinander. Ausserdem sollten wir da so nicht machen, da @data aus dem lokalen Bereich der Routine kommt, nicht aus dem globalen Heap. Wenn die Routine verlassen wird, kann data verschwunden sein und @data ins Niemandsland zeigen - nicht gut. Besser ist es also, einen mittels allocate() gewonnenen Heapzeiger zu verwenden. Die Umwandlung in einen typenlosen Zeiger geschieht über den Zwischenschritt eines typisierten Zeigers. Das geht:
DIM AS ttestdata PTR px1 DIM AS ANY PTR px2 px1=ALLOCATE(LEN(ttestdata)) px2=px1
Der Trick ist also, die Typumwandlung bei Zeigerzuweisungen zu benutzen. So. Nun können Sie cont auch als "any ptr" definieren. Machen Sie das und passen Sie Ihr Programm entsprechend an!
Theoretisch könnten Sie nun sogar in jedem Listenelement einen anderen Typ speichern. Sie können das sogar praktisch. Das ist allerdings ein grosser Nachteil. Wir haben bei Containern praktisch die Typenkontrolle verloren. Der Compiler kann uns nicht mehr darauf hinweisen, ob wir etwas, was eigentlich ein String sein soll, als Integer anfassen. Schlecht. Und daher ist es sehr ratsam, einen Teil der Typenkontrolle wieder nachzubauen. Dazu erweitern wir nun die Wurzel unserer Liste, die bisher nur aus einem Start-Zeiger besteht. Es ist ganz praktisch, noch ein paar weitere Informationen mit diesem Startzeiger zusammen zu bündeln:
TYPE tomalist start AS tomalist_element PTR last AS tomalist_element PTR current AS tomalist_element PTR size AS INTEGER typename AS STRING END TYPE
Wir haben "current" hinzugefügt, das auf die aktuelle Position in der Liste zeigt. Das ist ganz praktisch, wenn man Listen sequentiell durchläuft. Wir haben "size" hinzugefügt, um eine Kontrolle zu haben, wieviel Elemente unsere Liste schon hat. Und wir haben "typename" als String hinzugefügt. Dort können wir einen Typnamen für unsere Liste festlegen. Dieser Name muss nichts mit Basic-Typen zu tun haben. Er kann z.B. "strlist" heissen - ein Kürzel für "Stringliste". Wichtig ist nur, dass wir bei Abfragen und Speichervorgängen ebenfalls einen Typnamen verwenden. Stimmt dieser nicht mit der der Liste überein, lassen wir einen Typerror ausgeben. Z.B. heisst der Header der close-Funktion:
SUB omalist_close(BYREF list AS tomalist, typename AS string)
Oft sind Funktionen der Bearbeitung eines bestimmten Datentyps gewidmet. In diesem Fall werden wir z.B. viele Funktionen zum Bearbeiten von Objekten des Typs tomalist schreiben. Das erste Argument wird immer "byref list as tomalist" sein. Und wir werden immer mit bestimmten Elementen von tomalist arbeiten, mit .size, mit .start, mit .current usw. Es ist etwas umständlich, jedes Mal dann list.size, list.start, list.current zu schreiben - und überflüssig dazu - es ist ja klar, dass sich das alles auf list bezieht, ein anderes Objekt gibt's in der Funktion ja nicht.
Für diesen Zweck gibt's das WITH-Schlüsselwort:
WITH list IF (.size.... .current=.... ... END WITHInnerhalb des WITH-Blocks
Wir schreiben nun eine Reihe von Funktionen, die wir unserer tomalist zuordnen: Eine Funktion zum Initialisieren der Liste, eine zum Schliessen, eine zum Speichern. Speichern kann man auf zwei Arten: Man hängt ein neues Element hintendran. Oder man fügt eines an einer angegebenen Position ein. Das erstere ist einfacher.
Und wir müssen nun genau unterscheiden, was in der Speicherfunktion getan wird und was ausserhalb. Gespeichert wird in der Liste nur ein typenloser Zeiger. Sonst nichts. Um das Reservieren des Speichers und alles, was mit dem Inhalt hinter dem Zeiger zu tun hat, kann sich die Listenfunktion nicht kümmern - dazu müsste sie den Typ des Inhalts kennen.
So, nun schreiben Sie mal diese drei Funktionen. Die Anhäng-Speicher-Funktion nennen wir "omalist_push" und sie hat folgenden Header:
SUB omalist_push(BYREF list AS tomalist, px AS ANY PTR, typename AS string)
Hat's geklappt? Hier meine Versionen:
SUB omalist_init(BYREF list AS tomalist, typename AS string)
list.start=NULL
list.last=NULL
list.current=NULL
list.size=0
list.typename=typename
END SUB
' ------------------------------------------------------------
SUB omalist_close(BYREF list AS tomalist, typename AS string)
DIM AS INTEGER endoflist
DIM AS tomalist_element PTR curr
endoflist=FALSE
curr=list.start
WHILE(NOT endoflist)
'Gib zunaechst den durch cont reservierten Platz frei
DEALLOCATE(curr->cont)
'...und auch den Keyword-Speicherplatz
DEALLOCATE(curr->keyword)
'Schaue, ob es das letzte Element war
endoflist=(curr->nex=NULL)
IF (NOT endoflist) THEN
'Nein? Dann gehe mit curr eins weiter, damit das jetzige
'Element selbst freigegeben werden kann.
curr=curr->nex
DEALLOCATE(curr->prev)
ELSE
'Ja: Gib curr frei, Zeiger weg von curr werden ja nicht mehr benoetigt.
DEALLOCATE(curr)
END IF
WEND
END SUB
' ------------------------------------------------------------
SUB omalist_push(BYREF list AS tomalist, px AS ANY PTR, typename AS string)
'Haengt ein neues Element hinten an die Liste dran
WITH list
IF .typename<>typename THEN brkmess("tomalist, push(): typename error")
IF px=NULL THEN brkmess("tomalist, push(): content is NULL")
IF (.start=NULL) THEN
'Noch nichts in der Liste drin
'Erstmal ein Listenelement generieren. Das ist gleich das Startelement
.start=ALLOCATE(LEN(tomalist_element))
IF (.start=NULL) THEN brkmess("tomalist, push(): Error - allocation failed")
'Die Verweise vom Startelement weg muessen alle auf NULL sein, da ja noch
'kein anderes Element drin ist.
.start->nex=NULL
.start->prev=NULL
'Das letzte Element ist das erste
.last=.start
'Das aktuelle Element ist auch das erste
.current=.start
ELSE
'Fall: Schon was in der Liste gespeichert
'Erstmal ein Listenelement generieren, das ist gleich das aktuelle:
.current=ALLOCATE(LEN(tomalist_element))
'Verlinke das ehemals letzte Element mit dem jetzt aktuellen:
.current->prev=.last
.last->nex=.current
'Nach hinten hin gibts nichts zu verlinken, aktuelles ist ja das letzte Element:
.current->nex=NULL
'Und nun den Zeiger auf das letzte Element neu setzen:
.last=.current
'Das vorletzte Element erreichen wir weiterhin entweder ueber .start oder ueber
'.current->prev
END IF
'Und nun den Inhalt nicht vergessen:
.current->cont=px
.size+=1
END WITH
END SUB
Das ist hoffentlich selbsterklärend.
Ein grosser Vorteil von Listen ist, dass das Einfügen viel schneller geht als bei Arrays. Bei Arrays muss man immer den ganzen nachfolgenden Inhalt nach hinten schieben. Nicht so bei Listen: Einfach vier Zeiger passend setzen - das war's. Für das Einfügen muss allerdings erstens eine Position bekannt sein und zweitens muss bekannt sein, ob vor oder nach dieser Position eingefügt werden soll. Das ist für den Programmierer ein bisschen "touchy" alldieweil er jedes Mal berücksichtigen muss, dass sich die Einfügeposition auch am Rand der Liste befinden kann und daher "Davor" oder "Danach" bisher ausserhalb der Liste ist.
Wir führen also zwei Modi ein, die wir als globale Konstanten definieren:
const OMA_BEHIND=1 const OMA_BEFORE=-1
Ansonsten können Sie die Einfüge-Funktion analog zur Push-Funktion realisieren. Sie sollen folgenden Header haben:
SUB omalist_insert(BYREF list AS tomalist, position AS tomalist_element PTR, px AS ANY PTR, typename AS STRING, mode AS INTEGER = OMA_BEHIND)
Trick: Es empfiehlt sich, zunächst das neue Element zu generieren und dann sich gedanklich in die Position des neuen Elements zu versetzen: Wo vom neuen Element aus gesehen liegt nun die angegebene Position? Davor? OK, prev-Zeiger des neuen Elements auf die Position, nex-Zeiger der Position auf das neue Element. nex-Zeiger des neuen Elements auf das, was früher hinter der neuen Position kam, also auf position->nex. Und dessen prev-Zeiger auf das neue Element. Bei OMA_BEHIND siehts natürlich entsprechend anders aus.
Und hier mein Lösungsvorschlag:
' ------------------------------------------------------------
SUB omalist_insert(BYREF list AS tomalist, position AS tomalist_element PTR, px AS ANY PTR, typename AS STRING, mode AS INTEGER = OMA_BEHIND)
'Fuegt ein neues Element bei position in die Liste ein
'mode=-1: Vor position
'mode=1: Nach position
IF (mode<>OMA_BEFORE AND mode<>OMA_BEHIND) THEN brkmess("tomalist, insert(): mode out of range")
WITH list
IF .typename<>typename THEN brkmess("tomalist, insert(): typename error")
IF px=NULL THEN brkmess("tomalist, insert(): content is NULL")
IF (position=NULL) THEN brkmess("tomalist, insert(): position is NULL")
IF (.start=NULL) THEN
'Noch nichts in der Liste drin
'Funktioniert wie bei push()
'position wird nicht abgefragt.
.start=ALLOCATE(LEN(tomalist_element))
IF (.start=NULL) THEN brkmess("tomalist, insert(): Error - allocation failed")
.start->nex=NULL
.start->prev=NULL
.last=.start
.current=.start
ELSE
'Fall: Schon was in der Liste gespeichert
'Erstmal ein Listenelement generieren, das ist gleich das aktuelle:
.current=ALLOCATE(LEN(tomalist_element))
IF (mode=OMA_BEFORE) THEN
'Fuege .current zwischen position->prev und position ein:
.current->nex=position 'Rechts von .current kommt position
.current->prev=position->prev 'Links von .current kommt position->prev
IF (position->prev<>NULL) THEN 'position koennte ja .start sein...
position->prev->nex=.current 'Wenn nicht: Rechts von position->prev kommt .current
ELSE
.start=.current 'Wenn doch: Jetzt ist .current .start!
END IF
position->prev=.current 'Links von position kommt .current
ELSE
'Fuege .current zwischen position und position->nex ein:
.current->prev=position 'Links von .current kommt position
.current->nex=position->nex 'Rechts von .current kommt position->nex
IF (position->nex<>NULL) THEN 'position koennte ja .last sein...
position->nex->prev=.current 'Wenn nicht: Links von position->nex kommt current
ELSE
.last=.current 'Wenn doch: Jetzt ist .current .last!
END IF
position->nex=.current 'Rechts von position kommt current
END IF
END IF
'Und nun den Inhalt nicht vergessen:
.current->cont=px
.size+=1
END WITH
END SUB
Schon etwas verwirrend, soviele Zeiger. Aber effektiv. Wir werden das gleich sehen.
Nun sollten wir testen, ob unsere neuen Funktionen auch funktionieren. Wenn wir damit anfangen, stellen wir allerdings sehr schnell fest, dass wir gerne sehen wollen, was in unserer Liste drinsteht. Genau das aber geht nicht so einfach. Wir können nicht einfach kurz mal den Inhalt des fünften Elements auf den Bildschirm ausgeben.
Es empfehlen sich hier zwei Massnahmen: Benutzung des Debuggers gdb. Und das Schreiben von Logfiles.<7>p<
Mit dem Debugger kann man Schritt für Schritt den Einfügevorgang verfolgen und sich zumindest immer die Zeiger ausgeben lassen. Dann sieht man, an welcher Stelle jeweils der Nullzeiger kommt, welcher Zeiger der Startzeiger ist usw.
Noch besser ist es allerdings, sich eine Funktion zu schreiben, die Daten der ganzen Liste in ein extra File schreibt. So etwas nennt man ein "Logfile", zu Deutsch "Protokolldatei". Diese Routine kann man im Programm aufrufen, so oft man möchte. Dahinter dann am Besten ein "sleep" (oder man ist gerade im Debugger und geht sowieso schrittweise durch). Dann kann man das Logfile mit einem Editor anschauen und sieht, was zu diesem Zeitpunkt in der Liste steht. Das ist sehr praktisch. Schreiben Sie so eine Logging-Routine!
Bei mir sieht das so aus:
SUB omalist_log(BYREF list AS tomalist)
DIM AS INTEGER i
DIM AS tomalist_element PTR curr0
OPEN "log_list.txt" FOR OUTPUT AS #9
WITH list
curr0=.start
WHILE (curr0<>NULL)
? #9,.start,.size,.current,.current->nex
WEND
END WITH
CLOSE(1)
END SUB
Hier werden im Wesentlichen nur Zeiger ausgegeben, da die Routine allgemein gehalten wurde. Aber für Debuggingzwecke ist es natürlich sinnvoll, auch den spezifischen Inhalt von .cont mit auszugeben, also z.B. den String, auf den .cont ggf. zeigt.
Nun haben wir das Schwerste geschafft. Jetzt kommt der eher elegante Teil, nämlich das Auslesen. Hier ist es zweckmässig einige kleine Funktionen zu bauen:
Das ist nicht schwer, alles mehr oder weniger Dreizeiler. Hier meine Lösung:
' ------------------------------------------------------------
SUB omalist_setstart(BYREF list AS tomalist)
list.current=list.start
END SUB
' ------------------------------------------------------------
SUB omalist_setlast(BYREF list AS tomalist)
list.current=list.last
END SUB
' ------------------------------------------------------------
FUNCTION omalist_get(BYREF list AS tomalist) AS ANY PTR
'Gibt den Inhalt von .current zurueck
omalist_get=list.current->cont
END FUNCTION
' ------------------------------------------------------------
FUNCTION omalist_stepfwd(BYREF list AS tomalist) AS INTEGER
'Setze die aktuelle Position eins weiter
DIM AS INTEGER retval
retval=TRUE
'Aufgepasst! Wir koennen uns nicht drauf verlassen, dass
'der Nutzer das Ende der Liste abgepasst hat. .current kann NULL sein!
IF (list.current<>NULL) THEN list.current=list.current->nex
omalist_stepfwd=(list.current<>NULL)
END FUNCTION
' ------------------------------------------------------------
FUNCTION omalist_stepbwd(BYREF list AS tomalist) AS INTEGER
'Setze die aktuelle Position eins zurueck
DIM AS INTEGER retval
retval=TRUE
list.current=list.current->prev
omalist_stepbwd=(list.current<>NULL)
END FUNCTION
' ------------------------------------------------------------
FUNCTION omalist_getnext(BYREF list AS tomalist, BYREF endoflist AS INTEGER) AS ANY PTR
'Gibt den Inhalt von .current zurueck und setzt .current eins weiter
omalist_getnext=list.current->cont
endoflist=FALSE
WITH list
IF .current->nex<>NULL THEN .current=.current->nex ELSE endoflist=TRUE
END WITH
END FUNCTION
' ------------------------------------------------------------
FUNCTION omalist_getprev(BYREF list AS tomalist, BYREF endoflist AS INTEGER) AS ANY PTR
'Gibt den Inhalt von .current zurueck und setzt .current eins vor
omalist_getprev=list.current->prev
endoflist=FALSE
WITH list
IF .current->prev<>NULL THEN .current=.current->prev ELSE endoflist=TRUE
END WITH
END FUNCTION
Nun wollen wir das Ganze natürlich testen. Dazu speichern Sie sich einmal die HTML-Fassung von Kapitel 3.8 (kap38.htm), das erste Zeigerkapitel, als Datei ab. Sie können natürlich auch eine beliebige andere Textdatei nehmen. Schreiben Sie nun ein Testprogramm, das
Hier nur mein Beispiel für das Einlesen und Vorwärtsausgeben:
SUB testomalist1
DIM AS INTEGER i,j,endoflist,listok
DIM AS tomalist list
DIM AS STRING buf,a
DIM AS ZSTRING PTR zbuf
omalist_init(list,"string") '%%1
'Lies testweise hundert Zeilen von kap38.htm ein
? ">>>>>>>>> Read kap38.htm"
SLEEP
OPEN "kap38.htm" FOR INPUT AS #1
i=0
WHILE (NOT EOF(1))
INPUT$ #1,buf
testomalist_push(list,buf,i)
? i
i+=1
WEND
CLOSE #1
? ">>>>>>>>> Read done"
SLEEP
'Schauen wir uns das Gespeicherte an.
'Eine For-Schleife und Zaehlervariable brauchen wir nicht.
'Wir gebrauchen hier die omalist_Routinen
endoflist=FALSE
omalist_setstart(list)
WHILE (NOT endoflist)
zbuf=omalist_getnext(list,endoflist)
? *zbuf
WEND
? ">>>>>>>>>>>> Das war erstmal alles vorwärts"
omalist_setstart(list)
WHILE (NOT endoflist)
SCOPE
DIM s AS STRING
zbuf=omalist_getnext(list,endoflist)
s=*zbuf
IF (INSTR(s,"Zeiger")>0) THEN ? s
END SCOPE
WEND
? ">>>>>>>>>>>> Das war alles vorwärts, aber nur mit dem Wort 'Zeiger' "
omalist_close(list,"string")
END SUB
Vielleicht wird jetzt ein wenig klar, dass Listen nicht nur akademische Akrobatik sind, sondern sehr elegante und sichere Programmierung ermöglichen. Durch einen kleinen Kniff können wir die Listen noch wesentlich nützlicher machen. Es gibt ja zwei grundsätzliche Methoden, bestimmte Daten aufzusuchen. Die erste Möglichkeit ist, dass wir einen Zeiger haben. Das ist natürlich fein. Aber oft haben wir keinen Zeiger, sondern nur irgendetwas anderes Charakteristisches, eine Identifikationsnummer, einen Kennstring, einen Namen, eine postalische Adresse, eine Koordinate. Das "Charakteristische" ist dabei oft spezifisch für das Projekt und Objekt. Das heisst, man wird in einer Geometriesoftware z.B. die Objekte immer über die Koordinaten, nie aber über das Merkmal "Anzahl Polygone" aufsuchen. Und das können wir ausnutzen. Wir statten unsere Listenelemente mit einem zusätzlichen String-Pointer aus. Den wir "keyword" nennen:
TYPE tomalist_element prev AS tomalist_element PTR nex AS tomalist_element PTR cont AS ANY PTR keyword AS ZSTRING PTR END TYPE
Beim Speichern kann der User, wenn er mag, dieses Keyword mit angeben:
SUB omalist_push(BYREF list AS tomalist, px AS ANY PTR, typename AS STRING, keyword AS STRING="")
Innerhalb der Routine müssen wir das keyword natürlich abspeichern, so wie den Inhalt auch:
.current->keyword=allocate(len(keyword)+1)
*.current->keyword=keyword
Und nun kommt der Pfiff: Eine Routine omalist_find(list,keyword). Sie gibt den Inhalt des ersten Elements mit dem gesuchten keyword zurück. Schreiben Sie diese find-Routine!
Meine Lösung:
FUNCTION omalist_find(BYREF list AS tomalist, keyword AS STRING, mode AS INTEGER=0) AS ANY PTR
'Sucht Element mit keyword
'mode=OMALIST_START: Sucht von Anfang an vorwaerts
'mode=OMALIST_END: Sucht vom Ende weg rueckwaerts
'mode=OMALIST_FWD: Sucht von current position weg vorwaerts
'mode=OMALIST_BWD: Sucht von current position weg rueckwarts
DIM retval AS tomalist_element PTR
DIM AS INTEGER found,endoflist,direction,listOK
DIM AS ANY PTR result
found=FALSE
listOK=TRUE
result=NULL
IF mode=OMALIST_START THEN omalist_setstart(list)
IF mode=OMALIST_END THEN omalist_setlast(list)
direction=1
IF (mode=OMALIST_END OR mode=OMALIST_BWD) THEN direction=-1
WHILE (NOT found AND listOK)
IF (direction=1) THEN
result=omalist_get(list)
ELSE
result=omalist_get(list)
END IF
SCOPE
DIM AS STRING s1=*list.current->keyword
found=(s1=keyword)
END SCOPE
IF (direction=1) THEN listOK=omalist_stepfwd(list) ELSE listOK=omalist_stepbwd(list)
WEND
IF (NOT found) THEN result=NULL
omalist_find=result
END FUNCTION
Das ist natürlich nur eine Basislösung. Darauf aufbauend könnte man z.B. eine multifind-Routine schreiben, die alle Elemente mit dem gesuchten keyword aufsucht und in - ja warum eigentlich nicht? - in einer Liste zurückgibt. Ist ja kein grosses Problem, da nur Zeiger kopiert werden müssen, keine Inhalte.
Mittels omalist_find() können wir nun Listen auch als Arrays benutzen. Einfach den Index als LTRIM(STR(i)) an das Keyword übergeben und das entsprechende Element mit omalist_find() wieder aufsuchen. Das ist schon was Feines: Ein voll dynamisches Array, automatisch gerade immer so gross wie die Daten, die auch reingeschrieben wurden. Man kann es auch "löchrig" besetzen, d.h. Indizes auslassen. Kein Problem. Das Ärgste, was passieren kann, ist eine NULL-Rückgabe, weil das Element nicht gefunden wurde. Und auf die muss sowieso immer getestet werden.
Aber wir werden nun Arrays kaum mehr brauchen. Denn meist interessiert der Index ja gar nicht, sondern das, was dahinter steckt, also z.B. ein Schlüsselbegriff oder etwas, das zu einem Schlüsselbegriff gemacht werden kann. Man nennt so etwas auch einen "Hash". Haben wir es in einem Spiel z.B. mit Einheiten zu tun, so kann aus den Daten der Einheit vielleicht mittels dem Format "
Beim Testbeispiel, in dem Sie eine Textdatei einlasen, haben Sie wahrscheinlich schon von selbst eine Routine gebildet, die Ihnen beim Schreiben und Lesen die lästige Umformung von normalen Strings in any-Zeiger und zurück vornahm. Solche spezifischen Umformungsroutinen heissen "Wrapper". Grundsätzlich gilt auch hier wie meistens: So wenig Wrapper wie möglich, soviel wie nötig. Beispiel meines Stringlisten-Wrappers:
SUB testomalist_push(BYREF list AS tomalist, s AS STRING, i AS integer)
DIM AS ZSTRING PTR ps
DIM AS INTEGER slen
slen=LEN(s)
ps=ALLOCATE(LEN(s)+1)
*ps=s
'? "xxx >";str(i)
'sleep
omalist_push(list,ps,"string",STR(i))
END SUB
' ------------------------------------------------------------
FUNCTION testomalist_get(BYREF list AS tomalist) AS STRING
DIM AS ZSTRING PTR ps
DIM AS INTEGER endoflist
IF (list.size=0) THEN
testomalist_get=""
EXIT FUNCTION
END IF
ps=omalist_get(list)
testomalist_get=*ps
END FUNCTION
Zurück zu omalist_find(): Es hat noch einen eminenten Nachteil: Es wird bei grossen Listen extrem langsam. Klar: Es wird ja bei jedem Zugriff die ganze Liste durchgegangen. Das Zeitproblem kann schon anfangen, wenn Sie in einer Sekunde 10.000 Operationen durchführen wollen, die jeweils 100 Listenzugriffe benötigen und Ihre Liste hat 2.000 Einträge. Das bedeutet pro Sekunde das Anfassen von im Mittel 10.000 x 100 x 1000 = 1 Milliarde Listenelemente. Auf einem mittleren PC im Jahr 2006: Keine Chance. Im nächsten Kapitel werden wir uns mit einem Abkömmling der Listen beschäftigen, der schneller ist.
Die können Sie sich hier runterladen. Achtung! Sie ist noch für FBC 0.15, bei Benutzung von FBC 0.16 aufwärts muss die Besetzung der Konstanten TRUE und FALSE angepasst werden!