QBasic - Einführung in die Programmierung
Autor: Stephanie Heinrich
E-Mail: admin@forenpower.de
Ergänzungen und Korrekturlesen: Thomas Antoni
Datum: 19.06.2003 - 14.3.2004
Download nur von:
http://www.forenpower.de und
www.qbasic.de !
Ich habe eine kleine Serie mit QBasic Tutorials erstellt, um den Einstieg in diese
Sprache zu erleichtern. Grundvoraussetzung ist die QBasic- Programmierumgebung,
die Sie im
Downloadbereich von www.qbasic.de
herunterladen können.
Inhalt
1. Einführung in die Programmierung
2. Allgemeiner Programmaufbau
3. Einteilung der BASIC-Befehle
4. Verwendung der Funktionstasten
5. Verwendung von Tasten
6. Die Wertzuweisung
7. Winkelberechnung
8. Eine Zufallszahl erzeugen
9. Entscheidungen mit IF... THEN... ELSE
10. Fallauswahl mit SELECT CASE
11. Schleifen
12. Weitere Kontollstrukturen
13. Unterprogrammtechnik
14. Dateiverwaltung/ Sequenzielle Datei
15. Datentypen
16. Die Beispielprogramme - Übersicht
Erster Teil: Einführung in die Programmierung:
Damit der PC selbst einfachste Aufgaben erledigen kann, z.B. Informationen
speichern, Daten verknüpfen oder vergleichen, benötigt er eindeutige
Anweisungen. Die Summe einzelner Anweisungen wird als Programm (Software)
bezeichnet. Die Programme werden in Programmiersprachen erstellt, die ein PC in
Anweisungen mit Regeln für deren Anwendung umsetzen kann.
1. Begriffe
Die Software zur Erledigung einer Aufgabe wird als Anwendung oder auch
Applikation bezeichnet. Eine Anwendung besteht aus einem oder mehreren
Programmen. Weitere Programme dienen diesen Anwendungen indirekt, so
ermöglicht z.B. ein Netzwerktreiber den Transport von Daten. Dieser ist
dann eine Middleware, da er Verbindungen zwischen Programmen herstellt.
Die
Programme werden von der zentralen Recheneinheit (CPU) ausgeführt. Damit die
CPU die Befehle umsetzen kann, müssen sie in eine direkt von der CPU
lesbaren Sprache (Maschinensprache) geschrieben sein oder in diese
übersetzt, d.h. assembliert oder kompiliert werden.
2. Generationen der Programmiersprachen
2.1 Erste Generation
Die erste Programmiersprache wurde "maschinenorientierte Programmiersprache" oder
"Maschinensprache" genannt. Um sie von später entwickelten Sprachen zu
unterscheiden, bezeichnete man sie als Programmiersprache der "Ersten
Generation“, die sogenannte "First-Generation-Language" (1GL). In dieser Sprache
muss man alle CPU- Befehle direkt in Maschinensprache, also als Binärzahlen
("0/1-Kombinationen") aufschreiben.
2.2 Zweite Generation
Durch die Weiterentwicklung der 1GL zur Zweiten Generation, der sogenannten 2GL,
wurde das Problem der Lesbarkeit für den Menschen gelöst. Für
jeden Maschinenbefehl wird in der Sprache eine kurze, leicht zu merkende
Klartextbezeichnung (Mnemonik) definiert.
Für den Maschinenbefehl "123456" schreibt man z.B. "MOV A 456". Dies
bedeutet: Move (bewege/ speichere) den Inhalt von Register A nach Adresse 456 in
den Arbeitsspeicher (RAM).
Programme in den Sprachen der Zweiten Generation
können von der CPU nicht direkt ausgeführt werden. Deshalb wird ein
Übersetzerprogramm benötigt, ein sogenannter Assembler. Die Sprachen
der 2GL werden daher als Assembler bezeichnet. Die Vorraussetzung für die
Programmerstellung im Assembler sind gute Systemkenntnisse. Die
Assemblersprachen werden verwendet, wenn es auf höchste
Arbeitsgeschwindigkeit (Performance) und kleinsten Speicherplatzbedarf ankommt.
So sind z.B. Teile des Betriebsystems Windows in Assembler geschrieben. Auch die
Software, die nur auf spezieller Hardware eingesetzt wird, z.B. zur Steuerung von
Festplatten, Videorecordern, Handys, Waschmaschinen usw., wird zum Teil in
Assembler geschrieben. Solche Programme werden als Firmware bezeichnet.
2.3 Dritte Generation
Eine Programmiersprache der Dritten Generation (3GL) liegt vor, wenn eine
Mnemonik mehr als einen Maschinenbefehl beschreibt. Hier werden längere
Schlüsselwörter benutzt, um die Lesbarkeit für den Menschen zu
verbessern. Mann nennt diese Sprachen auch "Hochsprachen" oder "höhere
Programmiersprachen".
Beispiel:
do while (Datensatz vorhanden)
begin
read Datensatz
end
Die bekanntesten Programmiersprachen der Dritten Generation sind :
- Pascal, Delphi
- C, C ++
- BASIC (= Beginners All Purpose Symbolic Instruction Code)
- Fortran (= Formula Translation)
- Cobol (= Common Business Oriented Language)
An Schulen und in der Literatur werden am häufigsten die
Programmiersprachen Pascal und Objekt Pascal (Delphi) beschrieben. In der Praxis
wird heute jedoch vorwiegend C/C++ benutzt. In C/C++ werden:
- Betriebsysteme (Unix, Linux, Windows)
- Standardanwendungen (MS-Office, Star-Office, Open-Office)
- Individualanwendungen
- Spiele
programmiert.
2.4 Vierte Generation (4GL)
Heute werden Individualanwendungen zunehmend in einer 4Gl geschrieben. Eine 4GL
liegt vor, wenn ein Schlüsselwort komplexe Vorgänge beschreibt (z.B.
"readeach" bedeutet: "lese- alle-vorhandenen-Datensätze").
Kenntnisse
über Hardware oder Betriebsysteme sind für eine Programmierung in
einer 4GL nicht erforderlich, denn je höher eine Sprache entwickelt ist,
desto unabhängiger ist sie von den Betriebsystemen der PCs. 4Gl sind
Bestandteil einer Software-Produktions-Umgebung (SPU) oder eines Computer-Aided-
Software-Engineering-Tools (CASE-Tools).
2.5 Compiler und Interpreter
Die in den verschiedenen Programmiersprachen geschriebenen Programme, die
für einen Menschen gut lesbar sind, müssen für den Ablauf auf dem
Computer wieder in Maschinensprache übersetzt werden, damit die CPU die
Anweisungen ausführen kann. Diese Aufgabe übernehmen Compiler oder
Interpreter.
Der Compiler liest eine Textdatei, die das Programm (den Quelltext, auch
Sourcecode genannt) enthält, und übersetzt sie in die
Maschinensprache. Dabei entsteht eine neue Datei mit der Dateierweiterung ".EXE"
welche anschließend von der CPU ausgeführt wird. Dies bedeutet, der
Quelltext und der Compiler werden zur Ausführung des Programms nicht mehr
benötigt. Der Interpreter übersetzt den Quelltext nicht in
Maschinenbefehle, sondern analysiert (interpretiert) die Befehle während des
Programmablaufs und lässt sie dann von der CPU ausführen.
Dies
geschieht zeilenweise:
- Zeile, lesen, analysieren, ausführen
- Zeile, lesen, analysieren, ausführen
- Zeile, usw.
Es entsteht also kein Programm in Maschinensprache. Man benötigt deshalb
zum Ablaufen-Lassen dieses Programms immer den Interpreter und den Quelltext.
Dies bedingt eine wesentlich langsamere Programmausführung und einen
größeren Speicherplatzbedarf. Interpretersprachen haben den Vorteil
dass man die erstellten Programme besonders schnell ändern und erneut testen
kann.
Bei plattformunabhängigen Sprachen wie Java oder C# bezeichnet man den
Interpreter auch oft als "virtuelle Maschine".
QBasic 1.1 ist eine reine Interpretersprache. Mit QuickBasic 4.5 steht jedoch
ein zu QBasic 100%ig kompatibler Compiler zur Verfügung, mit dem man
BAS- Quellspracheprogramme zu direkt ausführbaren EXE-Programmen kompilieren
kann.
... zurück zum Inhaltsverzeichnis
Zweiter Teil : Allgemeiner Programmaufbau oder die Struktur eines Programms
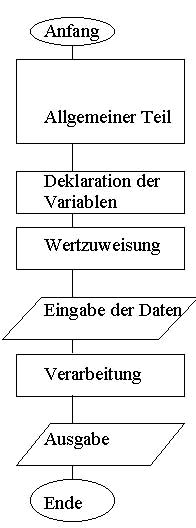
|
CLS
PRINT "Prg-Name: ..."
PRINT "Autor: ..."
PRINT "Daten: ..."
C = Hypothenuse
´B1 = Winkel in Grad
CONST PI = 3,14...
INPUT "Text", Variable
Gleichung
PRINT "Text"; Variable
PRINT "Textb"
|
... zurück zum Inhaltsverzeichnis
Dritter Teil : Einteilung der BASIC- Befehle
Die BASIC Programmbefehle lassen sich wie folgt einteilen:
- Eingabe- und Ausgabebefehle
- Rechenoperationen
- Schleifen
- Vergleiche
- Sprungbefehle
- Unterprogramme
- Funktionen
- Allgemeine Befehle
Die Ersten BASIC- Befehle
CLS clear screen
Syntax: CLS
CLS löscht den Bildschirm sowohl im Text- als auch im Grafikmodus.
REM remark
Syntax: REM <kommentar text>
Wenn eine BASIC- Zeile mit REM beginnt, so wird dies als Kommentar verstanden,
d.h. alle Zeichen hinter REM werden bei der Ausführung eines BASIC-
Programms nicht berücksichtigt. Falls REM nicht am Zeilenanfang steht, muss
vor REM ein " : " eingefügt werden (z.B. : REM Hallo). REM kann auch durch
das Hochkomma ersetzt werden (REM = ´ ).
END
Syntax: END
Jedes BASIC-Programm wird mit der Anweisung END beendet.
INPUT
Syntax: INPUT ["<Abfragetext>" {;|,} ] <Variablename>
Bei den Syntax-Angaben symbolisieren [eckige Klammern] Elemente, die man weglassen
kann, und senkrechte Striche "|" trennen mögliche Varianten eines Syntaxelements.
Mit INPUT werden sowohl numerische Variablen als auch String- Variablen
über die Tastatur eingelesen. Zunächst kann ein Abfragetext angezeigt werden.
Dann gibt man den Namen der Variablen an, in die der Eingabewert eingelesen
werden soll. Wenn hinter dem Abfragetext ein Semikolon (" ; ")
folgt, so wird an der Eingabe-Position auf dem Bildschirm ein Fragezeichen
ausgegeben:
INPUT "Ihr Alter";Alter
Kursiv : Text
Fett : Variable
Folgt nach dem Abfragetext dagegen ein Komma, so wird kein Fragezeichen ausgegeben.
INPUT "Ihr Vorname?",Vorname$
Kursiv : Text
Fett : Variable
PRINT
Syntax: PRINT ["<Text>"] [{; | ,}<Variablenname>...]
Mit PRINT können beliebige Zeichenketten oder numerische Werte auf den
Bildschirm ausgegeben werden. Bei der Anzeige mehrerer Textstücke (Strings)
werden diese durch Semikolons voneinander getrennt. Schreibt man statt des
Semikolons ein Komma, so erfolgt zwischen den Textstücken die Ausgabe eines
Tabulatorschritts. Normalerweise bedeutet das einen Spung zur
nächstgelegenen n x 14ten Bildschirmspalte (n = ganze Zahl = 1, 2, 3, ...).
PRINT "Ergebnis C=", C
Kursiv : Text
Fett : Variable
Mathematische Operationen
* Multiplikation
- Subtraktion
+ Addition
/ Division
SQR Quadratwurzel
^ Exponentialfunktion
... zurück zum Inhaltsverzeichnis
Vierter Teil : Die Verwendung von Funktionstasten
Die Anweisung KEY aktiviert, deaktiviert oder unterbricht die Ereignisverfolgung
einer Taste.
Ist die Ereignisverfolgung aktiviert, verzweigt KEY jedes mal zu
einem Unterprogramm, wenn die entsprechende Taste betätigt wurde. Mehr
Informationen zu Unterprogrammen gibt es in Teil 13.
Syntax: KEY (n %) ON
KEY (n %) OFF
KEY (n %) STOP
ON KEY (n %) GOSUB Unterprogrammname
n% : 1....10 = Funktionstasten F1...F10
30, 31 = Funktionstasten F11, F12
Eine Aufstellung der in der Klammer stehenden Tastencodes finden Sie in der
QBasic-Online-Hilfe unter "Hilfe | Inhalt | Tastatur-Abfragecodes".
... zurück zum Inhaltsverzeichnis
Fünfter Teil : Verwendung von Tasten
Mit der Anweisung INKEY$ wird ein Zeichen von der Tastatur gelesen. Das Zeichen
wird vom BASIC- Programm als ASCII- Code behandelt. Die ASCII- Codes der einzelnen
Tasten gehen aus der ASCII-Tabelle hervor, die in der QBasic-Onlinehilfe unter
"Hilfe | Inhalt | ASCII- Zeichen- Codes" verfügbar ist. Der Wert von INKEY$ kann
einer Variablen zugewiesen werden,
z.B. Taste$ = INKEY$.
Hinweise:
Taste$ = "" 'bedeutet ein "Leerstring" d.h. keine Taste gedrückt
Taste$ = CHR$ 'Taste mit ASCII-Code (106) d.h. "j" gedrückt
Taste$ = CHR$ 'Taste mit ASCII-Code (074) d.h. "J" gedrückt
Beispiel:
'Warteschleife durchlaufen bis
'die Esc- Taste gedrueckt wird
PRINT "Drücken Sie <esc>, um abzubrechen."
DO: LOOP UNTIL INKEY$ = CHR$(27) '27 = ASCII- Code für ESC
... zurück zum Inhaltsverzeichnis
Sechster Teil : Die Wertzuweisung
BASIC kennt keine mathematischen und physikalischen Konstanten (wie etwa Pi, g,
e, ...). Deshalb muss eine Konstante erst definiert werden, bevor man sie
verwenden kann. Diesen Vorgang nennt man Wertzuweisung.
Bei der Verwendung von Konstanten muss beachtet werden, dass BASIC keine
griechischen Zeichen als Variablen verarbeiten kann.
Syntax: CONST Konstantenname = Wert (ohne Einheit)
Beispiele für Wertzuweisungen an Konstanten:
CONST Pi = 3.141592654... 'Kreiskonstante
CONST g = 9.81 'Erdbeschleunigung
CONST e = 2.718281828... 'Eulersche Zahl
Die Wertzuweisung an Variablen lernen wir später in Teil 15 genau kennen. An dieser
Stelle nur ein paar Beispiele:
Beispiele für Wertzuweisungen an Variablen:
anna% = franz% * 215 'Wertzuweisung an numerische (Zahlen-) Variable
text$ = "Franz" 'Wertzuweisung an Textvariable (Stringvariable)
z = SQR(2) 'Wertzweisung von "Wurzel aus 2" an d.numerische Variable z
z = 5 ^ (-1 / 3) 'den Zahlenwert (1 / (3.Wurzel aus 5)) an z zuweisen
... zurück zum Inhaltsverzeichnis
Siebter Teil: Winkelberechnungen mit BASIC
Bei Winkeln verwendet man in der Mathematik 2 "Einheiten":
-
Das Gradmaß (Vollkreis entspricht 0°...360°)
- Das Bogenmaß (Vollkreis entspricht 0...2*Pi = 0...6,28 Radiant
= 0...6,28 rad)
Die Einheit "Radiant" (rad) ist eigentlich eine Zähleinheit und wird bei
Berechnungen nicht mitgeführt.
BASIC verwendet nur das Bogenmaß, deshalb benötigt man eine Gleichung
zum Umrechnen zwischen Gradmaß und Bogenmaß:
a in [rad] = a in [Grad] mal (Pi/180°)
Beispiel:
PRINT SIN (30 * 3.1416 / 180) 'sin (30°) anzeigen
... zurück zum Inhaltsverzeichnis
Achter Teil: Eine Zufallszahl erzeugen
Mit der Funktion "RANDOMIZE Startwert" wird der QBasic-Zufallsgenerator
aktiviert, und ein anschließender RND- Befehl erzeugt eine Zufallszahl zwischen
0.00000 und 0.99999 auf Grundlage des "Startwerts". Als Startwert verwendet man
über "RANDOMIZE TIMER" meistens den Inhalt der internen PC-Systemuhr, der
über die Systemfunktion TIMER abfragbar ist. Die Systemuhr hat nämlich
zum Zeitpunkt des Programmbeginns meist einen rein zufälligen Wert, sodass
das Programm immer mit anderen Werten startet.
Beispiel: Erzeugung einer Zufallszahl zwischen 0,0000 und 0,9999
CLS
PRINT "Prg.-Name: zz-1.BAS" 'Programmkopf anzeigen
...
RANDOMIZE TIMER 'Zufallsgenerator initialisieren
zz= 1* RND 'Zufallszahl zwischen 0,0000 und 0,9999 erzeugen
PRINT "zz = " ; zz '... und anzeigen
END
Beispiel: Erzeugung einer Zufallszahl zwischen 0 und 9,99999
Um eine Zufallszahl zwischen 0 und 9,99999 zu erhalten muss die
Zufallszahl mit dem Faktor 10 multipliziert werden.
CLS
PRINT "Prg.-Name: zz-2.BAS" 'Programmkopf anzeigen
...
RANDOMIZE TIMER 'Zufallsgenerator initialisieren
zz= (10 * RND) 'Zufallszahl zwischen 0.000 und 9,999 erzeugen
PRINT "Zufallszahl =", zz
END
Beispiel: Erzeugung einer ganzzahligen Zufallszahl zwischen 0 und 9
Mit der Funktion INT (Integer = Ganzzahl) schneidet man die Dezimalstellen ab und
erhält somit eine ganze Zahl.
CLS 'Bildschirm loeschen
PRINT "Prg.-Name: zz-3.BAS"
...
RANDOMIZE TIMER 'Zufallsgenerator initialisieren
zz = INT(10 * RND) 'Zufallszahl zwischen 0 und 9 erzeugen
PRINT "Zufallszahl =", zz
END
Beispiel: Erzeugung einer ganzzahligen Zufallszahl zwischen 5 und 9
Benötigt man eine ganzahlige Zufallszahl zwischen den zwei Grenzwerten
kzz und gzz, so verwendet man folgende Methode:
PRINT "Prg.-Name: zz-4.BAS"
...
kzz = 9 'kleinste Zufallszahl
kzz = 5 'groesste Zufallszahl
RANDOMIZE TIMER 'Zufallsgenerator initialisieren
zz = INT(RND * (gzz - kzz + 1)) + kzz 'Zufallszahl zwischen kzz und gzz
PRINT "Zufallszahl =" , zz
... zurück zum Inhaltsverzeichnis
Neunter Teil : Entscheidungen mit IF...THEN... ELSE
IF...THEN ELSE ist eine Funktion um "Entscheidungen" zu teffen.
Je nach Bedingung wird eine bestimmte Anweisung ausgeführt.
Syntax bei 2 Zweigen
IF Bedingung THEN
Anweisung 1
ELSE
Anweisung 2
END IF
Syntax bei mehreren Entscheidungen:
IF Bedingung 1 THEN
Anweisung 1
ELSEIF Bedingung 2 THEN
Anweisung 2
ELSE
Anweisung 3
END IF
Beispiel für mehrere Entscheidungen
INPUT "Gib eine Zahl zwischen 0 und 100 ein"; z
IF z < 50 THEN
PRINT "Die Zahl liegt zwischen 0 und 49"
ELSEIF z < 101 THEN
PRINT "Die Zahl liegt zwischen 50 und 100"
ELSE
PRINT "Falsche Eingabe, Zahl ist zu gross!"
END IF
... zurück zum Inhaltsverzeichnis
Zehnter Teil: Fallauswahl mit SELECT CASE
Die Mehrfach-Auswahl ist nicht abhängig davon, ob eine Bedingung wahr oder
falsch ist, sondern davon, welchen Wert eine Variable besitzt. Die Variable,
deren Inhalt geprüft werden soll, wird auch als Selektor bezeichnet. Der
Wert des Selektors bestimmt, welcher Anweisungsblock ausgeführt wird. In
der Programmierung wird auch hier von einer "Fallauswahl", "Fallunterscheidung",
"Mehrfachverzeigung" oder "Selektion" gesprochen. QBasic bietet hierfür den
Befehl SELECT CASE, zu deutsch "wähle einen Fall aus".
Syntax:
SELECT CASE Selektor
CASE Vergleichs-Selektor 1
Anweisung 1
CASE Vergleichs-Selector 2
Anweisung 2
CASE Vergleichs-Selektor 3
Anweisung 3
. . .
[CASE ELSE Vergleichs-Selektor n
Anweisung n]
END SELECT
Beispiel:
'Dies Beispiel zeigt einige Moeglickeiten des SELECT CASE Befehls
CLS 'Bildschirm loeschen
INPUT "Gib eine Zahl zwischen 0 und 10 ein"; z
SELECT CASE z
CASE 0: PRINT "Eingabewert ist 0"
CASE 1 TO 9
PRINT "Eingabewert liegt zwischen 1 und 9"
CASE 10: PRINT "Eingabewert ist 10"
CASE IS < 0
PRINT "Falsche Eingabe. Eingabewert ist negativ!"
CASE ELSE
PRINT "Falsche Eingabe. Eingabewert zu gross!"
END SELECT
Weiteres Beispiel: Siehe case-2.bas
... zurück zum Inhaltsverzeichnis
Elfter Teil: Schleifen
Die Wiederholung (Iteration) mit FOR...NEXT
Bei manchen Problemstellungen müssen Anweisungen mehrmals wiederholt
werden. Es wäre umständlich und mit viel Schreibarbeit verbunden, wenn
man jede Anweisung so oft schreiben würde, wie sie wiederholt werden
soll. Oft ist es auch nicht vorhersehbar, wie oft Anweisungen ausgeführt
werden sollen. In jeder Programmiersprache gibt es hierfür verschiedene
Kontrollstrukturen, auch Schleifen genannt. Die es ermöglichen,
Wiederholungen in knapper Form zu schreiben.
Eine Schleife besteht aus einer Schleifensteuerung und einem
Schleifenkörper. Die Schleifensteuerung gibt an, wie oft oder unter welcher
Bedingung die Anweisungen abgearbeitet werden. Der Schleifenkörper
enthält die zu wiederholenden Anweisungen.
Syntax:
FOR Zählvariable = Anfangswert TO Endwert
Anweisungen
NEXT Zählvariable
Beispiel:
'---- Anzeige der Wurzeln aus 2 bis 10 ---
FOR i% = 2 TO 10
PRINT SQR(i%)
NEXT i%
Die bedingte Wiederholung
Es ist nicht immer möglich, im voraus festzulegen, wie oft sich ein
Vorgang wiederholen soll. Dann ist es besser, wenn bei jedem Schleifendurchlauf
geprüft wird, ob der Schleifenkörper noch einmal durchlaufen werden
soll oder nicht. Man unterscheidet dabei die sogenannte kopfgesteuerte oder
fußgesteuerte Wiederholung.
Die kopfgesteuerte Wiederholung mit DO...LOOP
Bei einer kopfgesteuerten Schleife wird vor jeder Verarbeitung des
Schleifenkörpers eine Bedingung abgeprüft. Solange die Bedingung
am Anfang der Schleife erfüllt ist, werden die Anweisungen im Schleifenkörper ausgeführt.
Es kann auch vorkommen, dass die Schleife nicht durchlaufen wird,
nämlich dann, wenn die Bedingung nie erfüllt ist.
Syntax:
DO {WHILE|UNTIL} Bedingung
Anweisung
...
LOOP
Beispiele:
DO WHILE z <= 5 'Schleife wiederholen, solange
... 'z kleiner oder gleich 5 ist
LOOP
DO UNTIL z = 100 'Schleife wiederholen, bis das
... 'Ende-Kriterium z=100 erfuellt ist
LOOP
Die fußgesteuerte Wiederholung mit DO...LOOP
Bei der fußgesteuerten Wiederholung findet die Bedingungsprüfung am
Ende der Schleife statt. Nach Abarbeitung der Anweisungen wird geprüft, ob
der Schleifenkörper noch einmal durchlaufen werden soll oder nicht. Bis die
Bedingung erfüllt ist, werden die voraus gehenden Anweisungen wiederholt
ausgeführt.
Die fußgesteuerte Wiederholung wird eingesetzt, wenn
Programmteile mindestens einmal ausgeführt werden müssen. Erst dann
entscheidet eine Bedingungsprüfung, ob die Schleife wiederholt
ausgeführt wird.
Syntax:
DO
Anweisung 1
Anweisung 2
...
LOOP {WHILE | UNTIL} Bedingung
... zurück zum Inhaltsverzeichnis
Zwölfter Teil: Weitere Kontrollstrukturen
Sprunganweisungen mit GOTO
Eine GOTO-Anweisung veranlasst das Programm, von einer Stelle zu einer anderen
Stelle zu springen. Hinter der Anweisung GOTO folgt eine Sprungmarke (Label),
an die das Programm springen soll, falls die Bedingung erfüllt ist. Eine
GOTO-Anweisung kann beispielsweise für einen Schleifenabbruch
verwendet werden. Sie kann nicht dazu benutzt werden, in Unterprogramme wie
Prozeduren und Funktionen zu springen.
Syntax:
IF a > 10 THEN
GOTO Label
END IF
...
Label:
...
END
Schleifenabbruch mit EXIT
Es gibt die Möglichkeit, Schleifen in Abhängigkeit von einer
Bedingung zu verlassen, also frühzeitig zu beenden. Hierfür existiert
die Anweisung EXIT, die in allen Schleifenvarianten eingesetzt werden kann.
-
Eine zählergesteuerte Wiederholung wird mit EXIT FOR abgebrochen,
- Eine bedingte Wiederholung wird mit EXIT DO abgebrochen.
Syntax:
DO WHILE Zaehler > 0
....
IF Wert = 5 THEN
EXIT DO 'Schleife abbrechen
END IF
LOOP
....
... zurück zum Inhaltsverzeichnis
Dreizehnter Teil: Die Unterprogrammtechnik
Programme bzw. Programmteile, die immer wieder benötigt werden, müssen
nicht jedes Mal neu geschrieben werden. Sie werden als Unterprogramm (UP) nur
einmal geschrieben. Ein derartiges Unterprogramm (englisch "Subroutine", in
QBasic "SUB" genannt) steht immer am Ende eines Hauptprogramms (HP).
In Standard-BASIC wird ein Unterprogramm wird mit der Anweisung GOSUB
UnterprogrammName aufgerufen. Am Ende eines jeden Unterprogramms muss die
Anweisung RETURN stehen, damit das Programm wieder zum Hauptprogramm
zurückkehrt. Das Hauptprogramm wird mit der nächsten Programmzeile die
nach der Anweisung GOSUB steht fortgesetzt.
Diese Art von Unterprogrammen wird natürlich auch von QBasic untertsützt.
Bei QBasic verwendet man aber meist eine andere, komfortablere Art von
Unterprogrammen, die mit CALL UnterprogrammName
(ÜbergabeParameter) aufgerufen und in der Entwicklungsumgebung
über "Bearbeiten | Neue SUB" angelegt werden. In der Klammer lässt
sich an das Unterprogramm eine oder mehrere Variablen übergeben.
Solche "echten" Unterprogramme erscheinen in der QBasic-Entwicklungsumgebung
in eigenen Fenstern, die bequem über "Ansicht | SUBs" oder über die F2-Taste
erreichbar sind. Sie dürfen nicht mit RETURN abgeschlossen werden.
... zurück zum Inhaltsverzeichnis
Vierzehnter Teil: Dateiverwaltung- Sequenzielle Datei
Eine wesentliche Eigenschaft von Dateien besteht in der dauerhaften Daten-
Speicherung auf einem Datenträger (Diskette, Festplatte, usw.).
Eine Datei öffnen
Damit BASIC auf eine Datei zugreifen und Daten aus ihr lesen bzw. hinein
schreiben kann, muss die Datei zunächst geöffnet werden.
"Öffnen" bedeutet hier, dass der Ein- Ausgabekanal zum
Speichergerät (Diskette, Festplatte) eingeschaltet wird und die
entsprechende Datei vom Betriebsystem gesucht und für den Zugriff reserviert
wird. Auch das Anlegen einer neuen Datei geschieht durch das Öffnen.
Das BASIC-Schlüsselwort zum Öffnen einer Datei heißt OPEN.
Syntax:
OPEN <Dateiname> [FOR <Modus>] ...
... AS [#]<Dateinummer> [LEN = <Datensatzlänge>]
Eine Datei schließen
Wurde eine Datei geöffnet, so stellt BASIC ihr eine Anzahl von
Dateipuffern zur Verfügung. Dies sind Bereiche im Hauptspeicher des
Computers, in denen die Daten der Datei zwischengespeichert werden. Ist der
Datentransfer mit einer Datei beendet, so muss die Datei in jedem Fall wieder
geschlossen werden. D.h., dass die Inhalte der Dateipuffer in die gespeicherte
Datei zurückgeschrieben werden. Erst durch das Schließen von Dateien
ist eine korrekte Programmabwicklung gewährleistet.
Zum Schließen von Dateien, dient das BASIC-Schlüsselwort CLOSE
gefolgt, von der Nummer der zu schließenden Datei:
CLOSE #1
Eine Sequenzielle Datei zum Schreiben öffnen
Eine Sequenzielle Datei muss erst zum Schreiben geöffnet werden, bevor man dort
Daten eintragen kann. Dies erfolgt mit dem Befehl
OPEN <Dateiname> FOR OUTPUT AS #<Dateinummer>
Achtung: Existiert die Datei bereits, dann wird ihr Inhalt beim Öffnen
automatisch gelöscht!
Beispiel: Siehe Programm SEQWRITE.BAS
In eine Sequenzielle Datei schreiben
Zum Schreiben von Daten in eine Sequenzielle Datei dient das
BASIC-Schlüsselwort PRINT ergänzt um die Dateinummer und die zu
schreibende Information.
Syntax: PRINT #<Dateinummer> , <Text$>
Beispiel:
'Die Datei "tmp.txt" im Wurzelverzeichnis des Laufwerks C:\
'oeffnen und das Wort "Esel" hineinschreiben
OPEN "c:\tmp.txt" FOR OUTPUT AS #1
PRINT #1, "Esel"
CLOSE #1
Eine Sequenzielle Datei zum Lesen öffnen
Eine Sequenzielle Datei muss erst zum Lesen geöffnet werden, bevor man daraus
Daten lesen kann. Dies erfolgt mit dem Befehl
OPEN <Dateiname> FOR INPUT AS #<Dateinummer>
Beispiel: Siehe Programm SEQREAD.BAS
Aus einer Sequenziellen Datei lesen
Zum Einlesen von Daten aus einer Sequenziellen Datei dient die BASIC-Anweisung
INPUT gefolgt von der Dateinummer und nach einem Komma dem Namen der Variablen,
in die die gelesene Information eingetragen werden soll.
Syntax:INPUT #<Dateinummer> ,<Variablenname>
Beispiel:
'Inhalt der ersten Zeile der Datei "tmp.txt" im Wurzelverzeichnis
'des Laufwerks C:\ lesen und anzeigen:
OPEN "c:\tmp.txt" FOR INPUT AS #1
INPUT #1, text$
PRINT text$ 'und siehe da: Der "Esel" erscheint auf dem Bildschirm
CLOSE #1
Daten an eine Sequenzielle Datei anhängen
An die Sequenzielle Datei TEST.DAT sollen im nächsten Schritt noch
einige Datensätze angehängt werden. Mit dem Schlüsselwort
OPEN FOR APPEND werden Daten an den bereits vorhandenen Inhalt angehängt.
Siehe Programm: SEQAPP.BAS.
Random Datei
Will man in einer Sequenziellen Textdatei einen bestimmten Begriff suchen, so
muss man ein Programm schreiben, das die gesamte Datei Wort für Wort
einliest und durchsucht. Dies kann bei großen Dateien viel Zeit in
Anspruch nehmen. Deshalb muss man beim Speichern von Daten ein Verfahren
anwenden, bei dem Daten schnell gefunden werden. Dies wird in Form einer
"Tabelle" realisiert.
Das Prinzip einer Tabelle ist einfach. Sie besteht aus einer Anzahl von
nebeneinander angeordneten Spalten, deren Zweck durch eine Überschrift
gekennzeichnet ist. Die eigentlichen Daten werden in die einzelnen,
untereinander angeordneten Zeilen eingetragen, die man auch "Datensätze" nennt.
Zum Zwischenspeichern von Datensätzen für Random- Dateien wird häufig ein Feld
mit dem Benutzerdefinierten Datentyp verwendet (siehe TYPE...END TYPE
in Kapitel 15).
Beispiel:
Nachname Vorname Strasse Ort
Einstein Albert Einsteinstr. 3 München
Mozart Wolfgang Mozartgasse 1 Salzburg
Dürer Albrecht Dürerstr. 2 Nürnberg
Die Daten in Random- Dateien sind nach genau demselben, streng
strukturierten Muster einer Tabelle gespeichert. Jeder einzelne Datensatz hat
hier eine konstante Länge und ist in einzelne Datenfelder unterteilt, die
ihrerseits wieder eine konstante Länge aufweisen. Auf diese Weise
lässt sich die Position eines Datensatzes innerhalb einer Datei sehr
einfach berechnen.
Im Gegensatz zu Sequenziellen Dateien ist bei Random- Dateien ein beliebiger
Zugriff auch auf Datensätze mitten in der Datei möglich, ohne vorher alle
davor liegenden Daten lesen oder schreiben zu müssen (das engl. Wort "random" heißt
zu deutsch so viel wie "beliebig, wahlfrei").
Die allgemeine Formel zur Ansteuerung von
Datensätzen in einer Random- Datei lautet: (Datensatznummer – 1)*
Datensatzlänge. In der Praxis nimmt uns QBasic bei dem Arbeiten mit Random-
Dateien diese Berechnung weitgehend ab.
Eingaben von Daten in eine Random- Datei
Beispiel:
Siehe Programm "ADRESS5.BAS"
Eine Random- Datei öffnen
Zum Öffnen einer Random- Datei empfiehlt es sich stets, neben der
üblichen OPEN Formel zusätzlich die Länge eines Datensatzes
anzugeben. Dies geschieht mit Hilfe des Schlüsselwortes
LEN wie folgt:
OPEN "Adressen.Dat" FOR RANDOM AS #1 LEN = 60
In eine Random- Datei schreiben
Die einzelnen Datensätze werden mit der Anweisung PUT in die geöffnete
Datei geschrieben. Dabei muss die obligatorische Dateinummer (#1),
die Nummer des Datensatzes (i%) sowie das als Schreibpuffer zu verwendende
Benutzedefinierte Datenfeld und dessen Index (n%) angegeben werden.
PUT #1, i%, feld(n%)
Aus einer Random- Datei lesen
Das Lesen von Daten aus einer Random- Datei erfolgt mit dem Schlüsselwort
GET. Hier wird analog zum vorherigen Beispiel verfahren.
Beispiel:
Siehe Programm "ADRESS6.BAS"
Datensätze in einer Random- Datei suchen
Zum Suchen der Nummer der nächsten zum Zugriff vorgesehenen Datensatzes in
einer Random- Datei stellt QBasic das Schlüsselwort SEEK zur Verfügung.
Beispiel: Siehe Programm "ADRESS7.BAS"
Datensätze in einer Random- Datei löschen
Das unmittelbare Löschen von Datensätzen in einer Random- Datei
ist nicht vorgesehen. Die Datensätze einer Random- Datei können nur
überschrieben oder durch besondere Programmiermaßnamen mit
bestimmten Lösch-Zeichen gefüllt werden.
... zurück zum Inhaltsverzeichnis
Fünfzehnter Teil: Datentypen
Der Computer kann mit Zahlenwerten umgehen, beherrscht aber ebenso den Umgang
mit Textzeichen und Zeichenketten. Allerdings sind die Methoden, mit denen
einerseits Zahlen und andererseits Textzeichen bearbeitet werden können,
grundverschieden. QBasic hält für die verschiedenen Methoden der
Verarbeitung und Berechnung von Daten eine Reihe unterschiedlicher Datentypen
bereit. Zur Kennzeichnung des jeweiligen Datentyps einer Variablen werden die
Namen einer Variablen hinten mit einem zusätzlichem Zeichen, der so genannten
"Typenbezeichnung" versehen. Grundsätzlich unterscheidet QBasic zwei
Gruppen Datentypen:
- numerische Datentypen (Zahlenwerte)
- String-Datentyp (Textzeichen)
1. Numerische Datentypen
QBasic verlangt bei allen Zahlenwerten zur Kennzeichnung von Kommastellen
die amerikanische Schreibweise, den Punkt. Ein Komma führt zur Fehlermeldung!
Beispiel:
Wert = 2.7
a) Der Datentyp "INTEGER" (Ganzzahl)
Der Datentyp INTEGER kann ganzzahlige Werte im Bereich von – 32.768 bis + 32.767
aufnehmen. Dieser Datentyp belegt 2 Byte (16 Bit) an Speicherplatz. Die
Typenbezeichnung für den Variablennamen ist das Prozentzeichen (%).
Beispiel: Alter% = 16
b) Der Datentyp "LONG" (Lang-integer)
Hier lassen sich ganze Zahlen im Wertebereich von – 2.147.483.648 bis + 2.147.483.647
verarbeiten. Der Datentyp LONG benötigt im Hauptspeicher 4 Byte
( = 32 Bit). Die den Variablennamen anzuhängende Typenbezeichnung ist das Kaufmanns-Und
(&).
Beispiel: Anzahl& = 1600000
c) Der Datentyp "SINGLE" (Fließkomma- einfach genau)
Mit der Variablen vom Datentyp SINGLE lassen sich z. B. alle kaufmännischen
Berechnungen ausreichend genau ausführen. Die Zahlen werden mit einer Genauigkeit
von 6 Stellen nach dem Komma verarbeitet. Auch hier werden 4 Byte
( 32 Bit ) Speicherplatz belegt. Die Typenbezeichnung für den Variablennamen
ist das Ausrufezeichen (!).
QBasic ist standardmäßig auf den Datentyp SINGLE voreingestellt.
Fehlt im Variablennamen die Typenbezeichung, dann setzt QBasic den Datentyp
SINGLE voraus. Bei großen Zahlenwerten kann auch die
Exponentialschreibweise angewendet werden.
Beispiel:
Lichtgeschwindigkeit! = 2.997925 * 10E4 'Exponentialschreibweise
PRINT Lichtgeschwindigkeit! 'Anzeige: 299792.5
d) Der Datentyp "DOUBLE" (Fließkomma - doppelt genau)
Für viele wissenschaftliche Berechnungen genügt eine Genauigkeit von
6 Kommastellen nicht. Für derartige Fälle verwendet man den Datentyp
DOUBLE. Der hat eine Genauigkeit von 16 Stellen und verarbeitet Zahlenwerte
von – 1,7 * 10E308 bis + 1,7 * 10E308. Eine Doublezahl belegt 8 Byte ( 64 Bit)
Speicherplatz. Die Typenbezeichnung für den Variablennamen ist die Raute
(#).
Beispiel:
siehe Programm SONNE.BAS
2. Der Datentyp STRING
Der computertechnische Ausdruck für eine Kette von Textzeichen ist "String".
Zur Behandlung von "Strings" steht in QBasic ein einziger Datentyp zur
Verfügung: der Datentyp STRING. Er dient ausschließlich der
Verarbeitung von alfanumerischen Zeichen. Die Typenbezeichnung für
den Variablennamen ist das Dollarzeichen ($).
Beispiel:
EinName$ = "Albert Einstein"
PRINT EinName$
Damit QBasic erkennt, wo ein String beginnt und wo er endet, muss er in
Anführungszeichen gesetzt werden.
Beachte:
Um ein Anführungszeichen in einen String aufzunehmen, muss es mit
CHR$ (34) umschrieben werden.
Beispiel:
Weise$ = "Sokrates sagte: " + CHR$(34) + " Ich weiss, "
Weise$ = Weise$ + "dass ich nichts weiss" + CHR$(34) + "."
PRINT Weise$
CHR$(ASCII-Code) ist eine Textzeichenkette, die nur aus einem Zeichen mit dem
angegebenen ASCII-Zeichencode besteht (siehe auch die ACII-Tabelle in der
QBasic-Onlinehilfe unter "Inhalt | ASCII-Zeichen-Codes").
3. Benutzerdefinierte Datentypen
In QBasic kann man auch eigene Datentypen definieren. Ein Benutzerdefinierter
Datentyp kann sich aus beliebig vielen Variablen oder Arrays beliebiger Datentypen
zusammensetzen. Er wird von QBasic dann als selbständiger Datentyp
behandelt. Besonders in der Strukturierung von Random-Dateien und Datenbanken
wird von dieser Möglichkeit Gebrauch gemacht. Bevor wir mit diesem Datentyp
arbeiten, müssen wir ihn definieren. Dazu sind folgende Anweisungszeilen
erforderlich:
TYPE <Name des Benutzertyps>
<Elementname> AS <Typenbezeichnung>
[<Elementname> AS <Typenbezeichnung>]
[...]
END TYPE
DIM <Variablenname> AS <Name des Benutzertyps>
Erklärung der Syntax:
TYPE = QBasic- Schlüsselwort zur Einleitung einer Datentyp-
Definition. Als Name des Benutzertyps ist jeder beliebige Variablenname zulässig
AS = QBasic- Schlüsselwort zur Zuordnung eines Datentyps.
Angabe des Datentyps (alle Datentypen sind möglich)
[ ] = Die in eckigen Klammern aufgelisteten Begriffe können
nach Bedarf eingesetzt werden, sind jedoch nicht zwingend erforderlich.
[...] = Nach Bedarf eine beliebige Wiederholung der vorherigen
Anweisungszeilen
END TYPE = QBasic- Schlüsselwort zum Beenden der Datentyp-
Definition
DIM = Qbasic- Schlüsselwort zur Deklaration des
endgültigen Datentyp- Namens
Beispiel:
Siehe ADRESS1.BAS
4. Arrays
Als "Array", zu deutsch "Feld", bezeichnet man eine Variablenart, bei der unter
ein und dem selben Namen mehrere Elemente zusammengefasst werden können.
Damit man auf jedes einzelne Element Zugriff hat, werden die Elemente
durchnummeriert.
Für Array werden auch oft folgende Begriffe
verwendet:
- indizierte Variable
- Feld
- Vektor
Das Strukturprinzip von Arrays wird auch im Alltagsleben häufig angewendet.
Beispiel:
Sprichwort 1: Es ist nicht alles Gold, was glaenzt.
Sprichwort 2: Reden ist Silber, Schweigen ist Gold.
Sprichwort 3: Luegen haben kurze Beine.
Im Computer wird ein Array nach dem selben Muster aufgebaut.
Beispiel:
DIM Sprichwort$(20)
Sprichwort$(1) = "Es ist nicht alles Gold, was glaenzt."
Sprichwort$(15) = "Rede ist Silber, Schweigen ist Gold."
Sprichwort$(20) = "Luegen haben kurze Beine."
Ein Array dimensionieren
Mit der Zeile DIM Sprichwort$(20) wird QBasic mitgeteilt, dass
für das Array "Sprichwort$" ein Speicherraum von 21 Elementen
reserviert werden soll. Die einzelnen Feldelemente sind durchnummeriert und
über die Feldelement-Nummern zugreifbar. Die Feldelement-Nummern nennt man
"Indices" (Einzahl: "Index"). Die 21 Feldelemente des oben dimensionierten" Feldes
"Sprichwort$" lassen sich über die Indices 0 bis 20 ansprechen. Mit
Sprichwort(20)="Luegen haben kurze Beine" wird z.B. in das 21. Feldelement
ein String eingetragen. Man beachte, dass das erste Feldelement den Index "0" hat.
Es sind natürlich auch numerische Felder möglich. Mit DIM Alter#(12)
wird beispielweise ein Feld mit 13 DOUBLE-Werten dimensioniert.
Die einzelnen Elemente lassen sich mit den üblichen
Anweisungen weiter verarbeiten - oft auch in FOR...NEXT-Schleifen, in denen der
Feldindex hochgezählt wird.
Wenn in einer Anweisung die Array- Grenze überschritten wird, erscheint
die Fehlermeldung "Index außerhalb des Bereichs".
Beispiel:
Die Anweisung PRINT Sprichwort$(21) hat eine
Fehlermeldung zur Folge.
Mehr dimensionale Arrays
QBasic erlaubt die Einrichtung mehrdimensionaler Arrays. Die Struktur eines
zweidimensionalen Arrays lässt sich am besten mit einer Tabelle aus mehreren
Zeilen und Spalten vergleichen.
Beispiel: Zweidimensionales Array mit 6 Zeilen und 5 Spalten.
DIM Tabelle$(5,4)
Tabelle$(1,1) = "A"
Tabelle$(1,2) = "B"
Tabelle$(2,1) = "E"
Tabelle$(3,4) = "L"
Tabelle$(5,3) = "Y"
... zurück zum Inhaltsverzeichnis
Sechzehnter Teil: Beispielprogramme - Übersicht
Im Folgenden findet man eine Übersicht über die im Ordner "progs\" beiliegenden
Beispielprogramme. Durch Anklicken der Links kann man ein Programm "abspeichern",
anschauen oder starten.
... zurück zum Inhaltsverzeichnis
|